Metadata
Metadata provide information about your data. Structured metadata are intended to provide this information in a standardised way. The structured metadata are readable for both humans and machines. It can be used by data catalogues, for example DataCite Commons.
The standardisation of metadata involves the following aspects:
- Elements: rules about the fields that must be used to describe an object, for example the
title,authorandpublicationDate. - Values: rules about the values that must be used within specific elements. Controlled vocabularies, classifications and Persistent Identifiers are used to reduce ambiguity and ensure consistency, for example by using a term from a controlled vocabulary like the Medical Subject HEadings (MeSH) as a
subjectand an Persistent Identifier such as an ORCID to identify aperson. - Formats: rules about the formats used to exchange metadata, for example JSON or XML.
Metadata standards
Metadata standards allow for easier exchange of metadata and harvesting of the metadata by search engines. Many certified archives use a metadata standard for the descriptions. If you choose a data repository or registry, you should find out which metadata standard they use. At VU Amsterdam the following standards are used:
- Yoda uses the DataCite metadata standard
- DataverseNL uses the Dublin Core metadata standard
- VU Amsterdam Research Information System PURE uses the CERIF metadata standard
Many archives implement or make use of specific metadata standards. The UK Digital Curation Centre (DCC) provides an overview of metadata standards for different disciplines. The list is a great and useful resource in establishing and carrying out your research methodology.
Controlled Vocabularies & Classifications
Controlled vocabularies are lists of terms created by domain experts to refer to a specific phenomenon or event. Controlled vocabularies are intended to reduce ambiguity that is inherent in normal human languages where the same concept can be given different names and to ensure consistency. Controlled vocabularies are used in subject indexing schemes, subject headings, thesauri, taxonomies and other knowledge organisation systems. Some vocabularies are very internationally accepted and standardised and may even become an ISO standard or a regional standard/classification. Controlled vocabularies can be broad in scope or very limited to a specific field. When a Data Management Plan template includes a question on the used ontology (if any), what is usually meant is: is there a specific vocabulary or classification system used? The National Bioinformatics Infrastructure Sweden gives some more explanation about controlled vocabularies and ontologies. In short, an ontology does not only describe terms, but also indicates relationships between these terms.
Examples of controlled vocabularies are:
- CDWA (Categories for the Description of Works of Art)
- Getty Thesaurus of Geographic names
- NUTS (Nomenclature of territorial units for statistics)
- Medical Subject HEadings (MeSH)
- The Environment Ontology (EnvO)
Many examples of vocabularies and classification systems can be found at the FAIRsharing.org website. It has a large list for multiple disciplines. If you are working on new concepts or new ideas and are using or creating your own ontology/terminology, be sure to include them as part of the metadata documentation in your dataset (for example as part of your codebook).
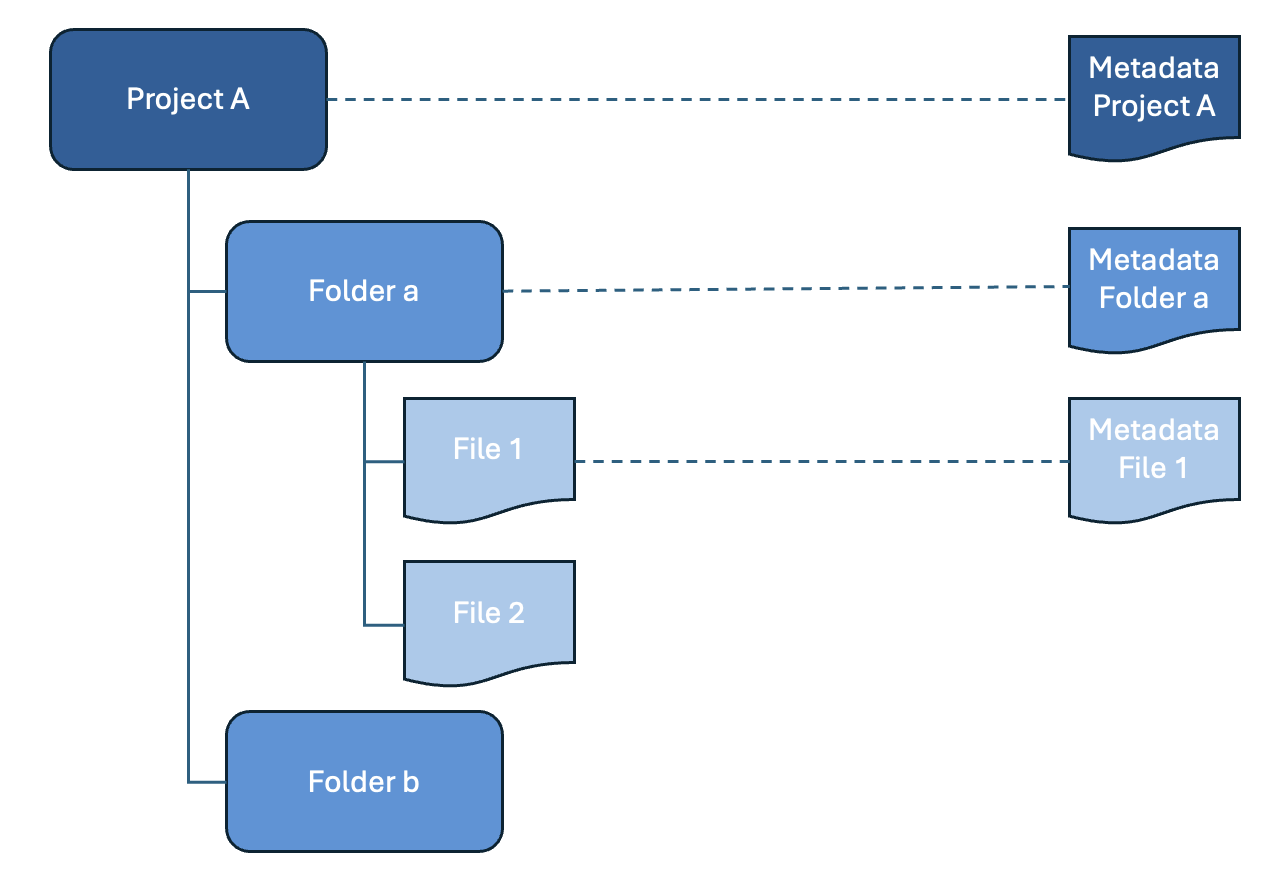
Metadata levels
Finally a distinction can be made on the level of description. Metadata can be about the data as a whole or about part of the data. It can depend on the research domain and the tools that are used on how many levels the data can be described. In repositories like Yoda and DataverseNL it is common practice to only create structured metadata on the level of the data as a whole. The Consortium of European Social Science Data Archives (CESSDA) explains this distinction for several types of data in their Data Management Expert Guide.
Dataset registration
When you want to make sure that your dataset is findable it is recommended that the elements of the description of your dataset are made according to a certain metadata standard that allows for easier exchange of metadata and harvesting of the metadata by search engines. Many certified archives use a metadata standard for the descriptions. If you choose a data repository or registry, you should find out which metadata standard they use. At VU Amsterdam the following standards are used:
- DataverseNL and DANS use the Dublin Core metadata standard
- VU Amsterdam Research Portal PURE uses the CERIF metadata standard
Many archives implement or make use of specific metadata standards. The UK Digital Curation Centre (DCC) provides an overview of metadata standards for different disciplines. The list is a great and useful resource in establishing and carrying out your research methodology. Go to the overview of metadata standards. More important tips are available at Dataset & Publication.